
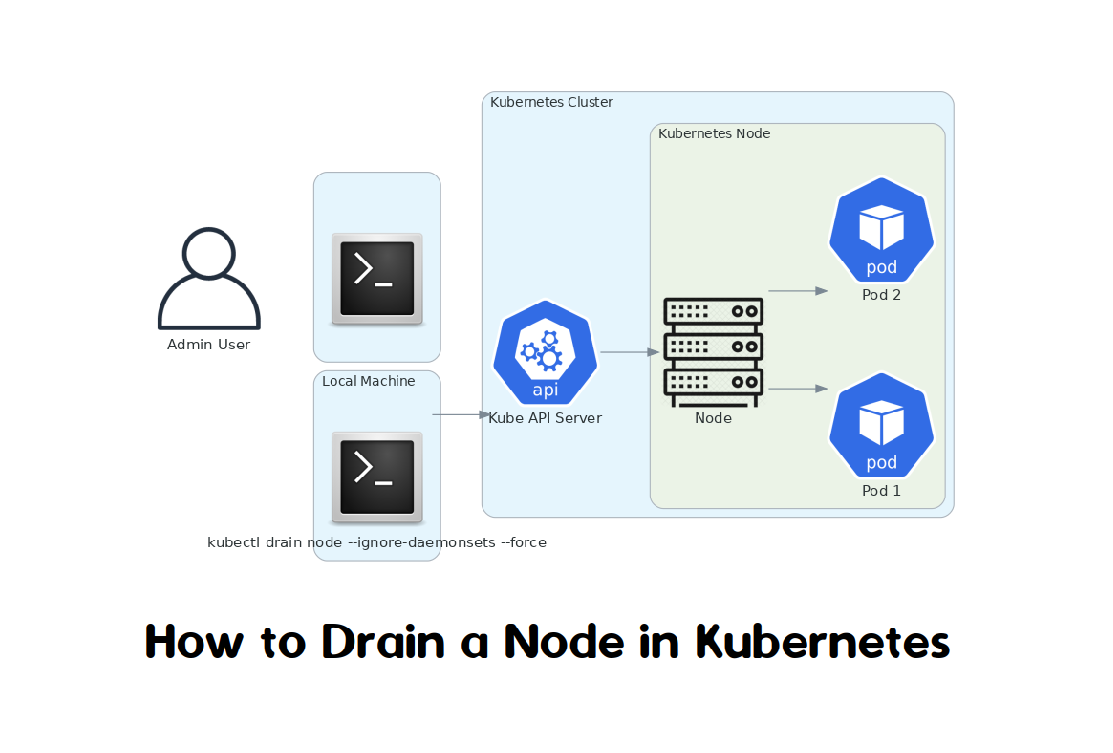
Node draining is the process of safely evicting all pods from a Kubernetes node. This is typically done for maintenance tasks, scaling down the cluster, or decommissioning a node. The kubectl drain command is used to achieve this, ensuring that the pods are rescheduled on other nodes in the cluster.
This guide provides an in-depth tutorial on how to drain a node in Kubernetes safely.
Table of Contents
Understanding Node Draining
When you drain a node, Kubernetes safely evicts all pods from the node, respecting the PodDisruptionBudget and ensuring that critical applications remain available. The process involves:
- Cordoning the node to prevent new pods from being scheduled.
- Evicting all pods, including managed pods (like those controlled by Deployments, ReplicaSets, etc.) and unmanaged pods (like those created directly without a controller).
Preparing for Node Drain
1. Before draining a node, verify the status of the node you intend to drain. This helps you ensure the node is healthy and currently schedulable.
# kubectl get nodesThis command lists all nodes in the Kubernetes cluster.
NAME STATUS ROLES AGE VERSION
node-1 Ready 10d v1.20.4
node-2 Ready 10d v1.20.4
node-3 Ready 10d v1.20.42. List all pods running on the node to understand the impact of draining it. This command shows which pods will be evicted during the draining process.
# kubectl get pods --all-namespaces --field-selector spec.nodeName=node-nameThis command retrieves all pods running on the specified node. This helps identify which applications and services will be affected by the node drain.
NAMESPACE NAME READY STATUS RESTARTS AGE
default my-app-1 1/1 Running 0 3d
default my-app-2 1/1 Running 0 3d
kube-system kube-proxy-node-1 1/1 Running 0 10d3. Ensure that your applications have appropriate PodDisruptionBudgets configured to maintain availability during the draining process.
# kubectl get poddisruptionbudgetsThis command lists all PodDisruptionBudgets in the cluster. This information helps ensure that draining the node won’t violate the application’s availability requirements.
NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE
my-app-pdb 1 N/A 1 5dDraining a Node
1. Cordon the Node
Cordoning the node prevents new pods from being scheduled. This is the first step in the draining process to isolate the node.
# kubectl cordon node-nameThis command marks the node as unscheduled, meaning no new pods will be scheduled on it.
node/node-1 cordonedThe output confirms that the node has been successfully cordoned, indicating it is now isolated for draining.
2. Drain the Node
Draining the node evicts all pods from it. This command ensures that all pods are safely rescheduled to other nodes.
# kubectl drain node-name --ignore-daemonsets --delete-emptydir-dataThe command starts the process of evicting all pods from the node. The output shows which pods are being evicted and confirms their eviction. DaemonSet-managed pods are ignored because they are expected to run on all nodes, and pods using emptyDir volumes are forcibly deleted.
node/node-1 already cordoned
WARNING: ignoring DaemonSet-managed pods: kube-system/kube-proxy-node-1
evicting pod default/my-app-1
evicting pod default/my-app-2
pod/my-app-1 evicted
pod/my-app-2 evictedCommand Breakdown:
- –ignore-daemonsets: DaemonSet pods are not evicted because they are expected to run on every node.
- –delete-emptydir-data: This flag forces deletion of pods that use emptyDir volumes, which might otherwise block the drain.
Monitoring the Drain Process
1. Check Node Status
Ensure the node is in a drained state and unschedulable.
# kubectl get nodesThe command lists all nodes and their statuses. The drained node should have a status of “Ready,SchedulingDisabled,” indicating that it is still healthy but not accepting new pods. This confirms the node has been successfully drained.
NAME STATUS ROLES AGE VERSION
node-1 Ready,SchedulingDisabled 10d v1.20.4
node-2 Ready 10d v1.20.4
node-3 Ready 10d v1.20.42. Monitor Evicted Pods
Check the status of the evicted pods to ensure they are rescheduled on other nodes.
# kubectl get pods --all-namespacesThe output helps verify that the evicted pods have been rescheduled on other nodes, ensuring the applications remain running and available.
NAMESPACE NAME READY STATUS RESTARTS AGE
default my-app-1 1/1 Running 0 5m
default my-app-2 1/1 Running 0 5m
kube-system kube-proxy-node-2 1/1 Running 0 10d3. Event Logs
Review event logs to track the draining process and any issues that may have occurred.
# kubectl describe node node-nameThis command provides detailed information about the node, including recent events and conditions. The output helps track the draining process, check for any issues, and confirm the node’s status after draining.
Name: node-1
Roles:
Labels:
Annotations:
CreationTimestamp: ...
...
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
Ready False 2024-07-09T12:00:00Z 2024-07-09T12:00:00Z KubeletReady kubelet is posting ready status
...Managing Drained Nodes
Once the node is drained, you can perform maintenance tasks. After maintenance, you can uncordon the node to make it schedulable again.
Uncordoning the node allows new pods to be scheduled.
# kubectl uncordon node-nameThis command marks the node as schedulable again. The output confirms that the node has been successfully uncordoned, indicating it is ready to accept new pods and participate fully in the cluster again.
node/node-1 uncordonedCommon Errors and Their Solutions
Error 1: Pod Eviction Timed Out
Description: When trying to drain a node, you might encounter an error where the eviction of a pod times out.
Solution:
This usually happens if the pod cannot be safely evicted due to constraints such as PodDisruptionBudget or if it is taking too long to terminate. To address this, you can:
1. Increase Timeout:
# kubectl drain node-name --timeout=5mThis command increases the timeout period, giving the pods more time to terminate gracefully.
2. Force Eviction:
If safe to do so, you can force the eviction.
# kubectl drain node-name --force --grace-period=30This command forces the eviction of the pods, reducing the grace period to 30 seconds.
Error 2: DaemonSet Pods Are Not Evicted
Description: DaemonSet pods are not evicted by default when draining a node.
Solution:
This behavior is expected as DaemonSet pods are designed to run on every node. To ignore DaemonSet pods during draining, use:
# kubectl drain node-name --ignore-daemonsetsThis command allows the drain operation to proceed without evicting DaemonSet-managed pods.
Error 3: Pod with local storage not evicted
Description: Pods using emptyDir volumes are not evicted by default.
Solution:
To force eviction of these pods, use the –delete-emptydir-data flag.
# kubectl drain node-name --delete-emptydir-dataThis command forces the deletion of pods that use emptyDir volumes, ensuring the node can be drained.
Error 4: Insufficient Cluster Capacity
Description: If the cluster does not have enough resources to reschedule the evicted pods, the drain operation might fail.
Solution:
Check cluster capacity and ensure there are enough resources (CPU, memory) to accommodate the evicted pods on other nodes. Consider adding more nodes to the cluster or freeing up resources.
Error 5: Stuck in Cordoned State
Description: After cordoning a node, you might find it stuck in a cordoned state and unable to be drained.
Solution:
Check for any pending operations or pods that cannot be evicted. Resolve any issues and then proceed with draining. If necessary, uncordon and cordon the node again.
# kubectl uncordon node-name && kubectl cordon node-nameThis sequence of commands uncordons the node and then cordons it again, helping to reset the state and allow for successful draining.
Conclusion
Draining nodes in Kubernetes is crucial for maintaining cluster health and performing maintenance tasks. By following the steps outlined in this guide, you can safely drain nodes while ensuring minimal application disruption. Always follow best practices and monitor the process to maintain a smooth and efficient operation.
FAQs
1. Can I drain a node without affecting DaemonSet pods?
Yes, by default, kubectl drain ignores DaemonSet pods, so they will continue running on the node.
2. How do I make a node schedulable again after draining it?
You can make the node schedulable again by running: kubectl uncordon node_name
3. What’s the difference between kubectl cordon and kubectl drain?
kubectl cordon marks the node as unschedulable but doesn't evict any pods. While kubectl drain marks the node as unschedulable and evicts all non-DaemonSet pods.
4. What should I do if a node fails to drain properly?
If a node fails to drain, ensure that there are no pods stuck in a terminating state. You may need to use the --force flag to forcibly evict them.


